Please refer to Multiple user task instances for an explanation of the differences between form data in sequential and parallel user task instances.
When using a subprocess task, it can be decided whether the workflow should create a shared process instance for the main process and the subprocess(es), or whether it should create a separate process instance for each subprocess of the task.
To work with only one process instance, select "Shared Process Instance" in the "Subprocess Properties".
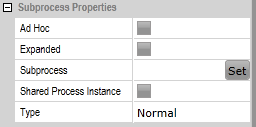
A difference between the two variants is the use of data. If subprocesses are generated as separate process instances, (for example) additional steps are required to transfer data from one process instance to another. These aren't required for a shared process instance.
A token that arrives at a multiple (subprocess) task is split according to the entries in the collection. For this reason, there is a difference between a shared and a separate process instance. In the context of a separate process instance, a separate process instance is created for each token generated in a multiple subprocess task. The workflow can recognize which token is assigned to which subprocess. For a shared process instance, exactly this token-level differentiation still needs to take place.
The following table provides an overview of possible combinations for a multiple subprocess task with regard to their form data usage:
parallel |
sequential (the use of private instance attributes in sequential subprocesses is not available) |
|||
private instance attributes |
||||
no |
yes |
|||
shared process instance |
yes |
If you use a shared process instance and no private instance attributes,
|
If you use a shared process instance and private instance attributes,
|
If you use a shared process instance, there is no separation between the data of the main process and the data of the subprocesses. You don't need to import the variables of the main process into the subprocess or export them out of the subprocess. The sequential subprocesses are executed one after the other and use the data of the previous subprocess. |
no |
If you don't use a shared process instance or private instance attributes,
|
(the use of private instance attributes is not available) |
If you don't use a shared process instance, a separate process instance is created for each token generated in a multiple subprocess task in addition to the main process. To use the data of the main process in the subprocess, you need to import the variables into the subprocess. Export them out of the subprocess to get them back into the main process. The sequential subprocesses are executed one after the other and use the data of the previous subprocess. |
|
Example: inventory check for an order
In this example, we are an online store and receive an order for multiple items. It is now necessary to check whether the stock of this article is sufficient.
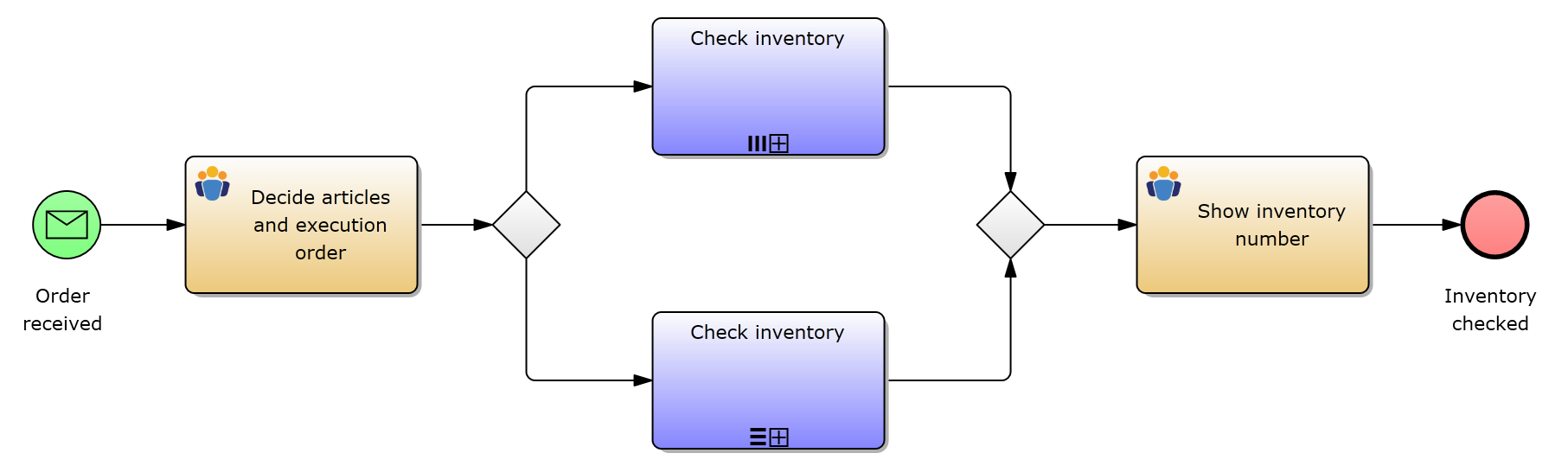
In the form of the first user task you can see (for example) the article number of the article to be checked as well as decide whether the inventory check should be parallel or sequential.
In the subprocesses happen the actual inventory checks.
The form of the last user task will show you (at least) the current number of articles in stock, which has been determined in the subprocesses. In this example the data will be displayed in a data grid.
The following workflow properties have been set for the multiple subprocess task:
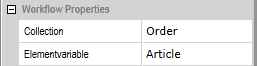
No Private Instance Attributes
The following variables have been set for the process:
MainData
MultipleData
Order
Article
In preparation for the first user task the variables must be defined as follows:
MainData = {}
MultipleData = {}
Order = []
So we have an array "Order" that will consist of the article numbers of the articles for which we need to check the inventory, and a dictionary "MainData" in which we want to collect the data of the whole process as well as a "MultipleData" for the data in the multiple subprocesses.
Since each subprocess has its own process instance, the process instances do not know of the other's form data. You need to import and export the associated variables. The Collection is directly linked to the subprocesses through the setting of the workflow properties, so you don't have to import or export that variable. In separate process instances the workflow can recognize which article number belongs to which subprocess. Because of that you don't address the token to get the value of the Elementvariable (the article number) of the Collection, but address the Elementvariable previously set as a global variable.
So getting the data of MainData into MultipleData could be done with the following Python code:
MultipleData[Article] = MainData
In order to transfer the data collected in the subprocess and stored in MultpleData back into the main process for further use, the data structure must be compatible. Since the multiple subprocesses use the advanced mode, the data must be prepared.
In this example the information gathered in the subprocess is to be displayed in a data grid, so the values of the keys in the dictionary "MultipleData" must be transferred into the variable of a data grid in "MainData". This could be done with the following Python code:
MainData["Grid"] = MultipleData.values()
Differences depending on execution order
MultipleData = {"<Article 1>": {"article number": "1234", "stock": "3"}, "<Article 2>": {"article number": "5678", "stock": "5"}}
Parallel Subprocesses
When the parallel subprocess tasks are completed, "MainData" contains only the data of the last completed subprocess. It would look like this:
MainData = {"grid": [{"article number": "5678","stock": "5"}]}
In order to get the data of each of the parallel subprocesses back into the main process, you have to either use the Private Instance Attributes as described below or work with data stores.
Sequential Subprocesses
When the sequential subprocess tasks are completed, the data of "MainData" would look like this:
MainData = {"grid": [{"article number": "1234", "stock": "3"}, {"article number": "5678","stock": "5"}]}
The following variables have been set for the process:
MainData
MultipleData
Order
In preparation for the first user task the variables must be defined as follows:
MainData = {}
MultipleData = {}
Order = []
So we have an array "Order" that will consist of the article numbers of the articles for which we need to check the inventory, and a dictionary "MainData" in which we want to collect the data of the whole process as well as a "MultipleData" for the data in the multiple subprocesses.
Since there is only one process instance, the subprocesses know the form data of the main process. Therefore, you don't need to import or export any variables. In separate process instances the workflow can recognize which article number belongs to which subprocess. For a shared process instance, exactly this token-level differentiation still needs to take place. Because of that you address the token to get the value of the Elementvariable (the article number) of the Collection.
So getting the data of MainData into MultipleData could be done with the following Python code:
MultipleData[Token.Attributes["Article"]] = MainData
In order to transfer the data collected in the subprocess and stored in MultpleData back into the main process for further use, the data structure must be compatible. Since the multiple subprocesses use the advanced mode, the data must be prepared.
In this example the information gathered in the subprocess is to be displayed in a data grid, so the values of the keys in the dictionary "MultipleData" must be transferred into the variable of a data grid in "MainData". This could be done with the following Python code:
MainData["Grid"] = MultipleData.values()
The data in MultipleData that looks like this:
MultipleData = {"<Article 1>": {"article number": "1234", "stock": "3"}, "<Article 2>": {"article number": "5678", "stock": "5"}}
will then be transferred into the grid in MainData and have the standard grid structure:
MainData = {"grid": [{"article number": "1234", "stock": "3"}, {"article number": "5678","stock": "5"}]}
Using the Private Instance Attributes
The Private Instance Attributes are only available for parallel subprocesses with shared process instances. For shared process instances, this feature separates the data for each subprocess. So by using the Private Instance Attributes, the attributes are stored in datasets. It is then possible to access the attributes via these datasets.
To work with the Private Instance Attributes, select the check box in the workflow properties. There you can also choose a name for the Private Instance Attribute Identifier.
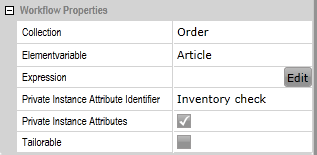
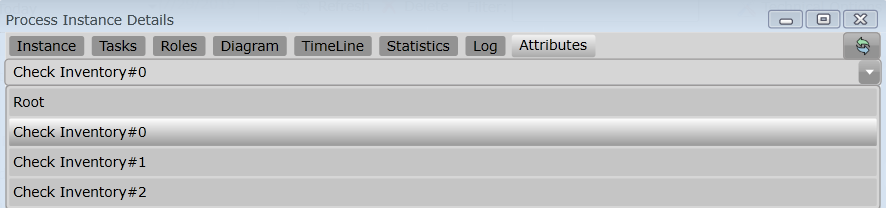
In the Process Instance Details, the attributes of the subprocesses are displayed separately:
The following variables have been set for the process:
MainData
MultipleData
Order
In preparation for the first user task the variables must be defined as follows:
MainData = {}
MultipleData = {}
Order = []
So we have an array "Order" that will consist of the article numbers of the articles for which we need to check the inventory, and a dictionary "MainData" in which we want to collect the data of the whole process as well as a "MultipleData" for the data in the multiple subprocesses.
Although you have a shared process instance, because you use the private instance attributes, you need to import the associated variables into the subprocesses. The Collection is directly linked to the subprocesses through the setting of the workflow properties, so you don't have to import or export that variable. In separate process instances the workflow can recognize which article number belongs to which subprocess. For a shared process instance, exactly this token-level differentiation still needs to take place. Because of that you address the token to get the value of the Elementvariable (the article number) of the Collection.
So getting the data of MainData into MultipleData could be done with the following Python code:
MultipleData[Token.Attributes["Article"]] = MainData
Using the private instance attributes separates the data for each subprocess and stores the attributes in datasets. In order to transfer the data collected in the subprocess back into the main process for further use, the data structure must be compatible. Since the multiple subprocesses use the advanced mode, the data must be prepared.
In this example the information gathered in the subprocess is to be displayed in a data grid, so the values of the keys in the dictionary "MultipleData" must be transferred from the datasets into the variable of a data grid in "MainData". This could be done with the following Python code:
MainData["grid"] = []
Root = ProcessInstance.GetRootDataSet()
SubDataSets = Root.GetSubDataSets()
for ds in SubDataSets:
subdata = ds.GetAttribute("MultipleData")
MainData["grid"].extend(subdata.values())
The data in MultipleData that looks like this:
Check Inventory #0: MultipleData = {"<Article 0>": {"article number": "1234", "stock": "3"}}
Check Inventory #1: MultipleData = {"<Article 1>": {"article number": "5678", "stock": "5"}}
will then be transferred into the grid in MainData and have the standard grid structure:
MainData = {"grid": [{"article number": "1234", "stock": "3"}, {"article number": "5678","stock": "5"}]}